




 17
17 Like
Like Share
Share
 Report
Report
Here is a very popular AI service offered by Azure AI, that can just not decode any text to speech, but also can convert speech to text as well. Yeah, you heard me right -- it can do so effortlessly and with absolute accuracy.
Given the speed and accuracy with which it can do the same, it can help any business, in a lot many areas, viz.,
a. Helping Specially abled readers to communicate/interact with outside world
b. Integrating any speech to be apprehended and saved as media (sound) file as a Blob or a SharePoint attachment.
c. Buget friendly and auto-scaleable.
d. Selecting your preferred model (accent, gender, impetus, emphasis) for the voice generator
e. Real time/near real time integration abilities
Create an Azure AI speech resource
Here is an example that can help you in implementing the same.Reach out to https://portal.azure.com and create the following resource: Speech Service --

Here are the details:
1. Select a proper resource group/create a new one
2. Give a suitable name
3. Select a suitable region
4. Pricing tier is what you should choose to decide the obbvious cost implications. For a complete pricing details, click on the following URL: https://go.microsoft.com/fwlink/?linkid=2100053
Ensure to select System assigned managed security:

Click on Review + Create >> Create to Continue.
The resource will take a while to get deployed under the selected resource group.

This is the default landing page to Azure AI speech. You can browse down to Speech studio and try out various manual utilities available out of box:

Text to speech
Here is a small C# code that can convert any speech to text:
a. Start with a Windows + Console Project >> and right click on your project area >> select Manage Nuget Packages >> search and install Microsoft.CognitiveServices.Speech and Microsoft.CognitiveServices.Speech.audio.
b. Define the variables under LocalSettings.Json:
speechKey and speechRegion,
which you can get as under
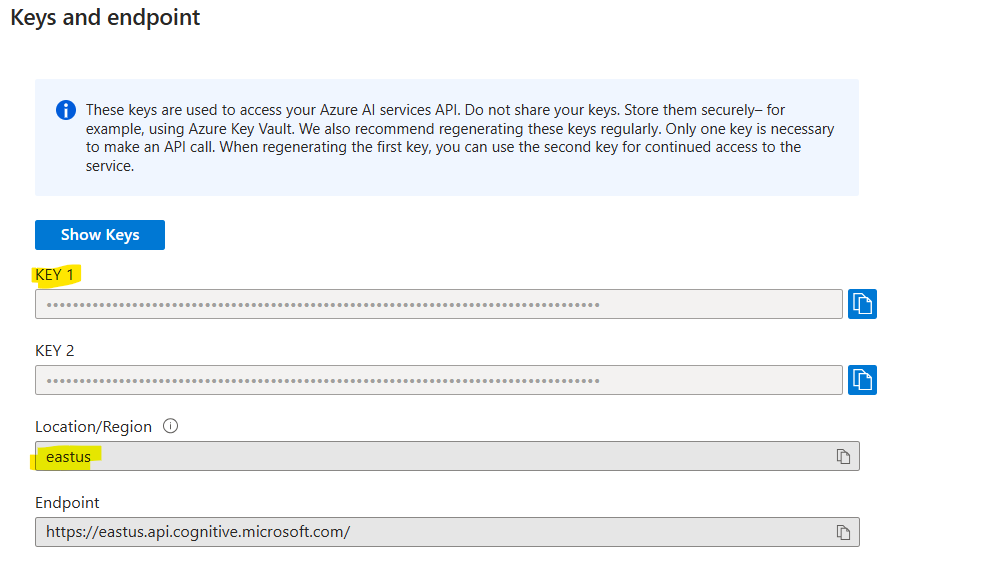
using System;
using System.IO;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
static void OutputSpeechRecognitionResult(SpeechRecognitionResult speechRecognitionResult)
{
switch (speechRecognitionResult.Reason)
{
case ResultReason.RecognizedSpeech:
Console.WriteLine($"Decoded: Text= {speechRecognitionResult.Text}");
break;
case ResultReason.NoMatch:
Console.WriteLine($"NOMATCH: Speech could not be recognized.");
break;
case ResultReason.Canceled:
var cancellation = CancellationDetails.FromResult(speechRecognitionResult);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={cancellation.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you set the speech resource key and region values?");
}
break;
}
Console.ReadKey();
}
The above code is a method that accepts any inputted text and converts it into speech, by invoking the speech calss: SpeechRecognitionResult . If any error is there, it would simply break and cause an API cancellation.
Let us now call this method from the Main:
async static Task Main(string[] args)
{
var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion);
speechConfig.SpeechRecognitionLanguage = "en-US";
using var audioConfig = AudioConfig.FromDefaultMicrophoneInput();
using var speechRecognizer = new SpeechRecognizer(speechConfig, audioConfig);
Console.WriteLine("Say something now:");
var speechRecognitionResult = await speechRecognizer.RecognizeOnceAsync();
OutputSpeechRecognitionResult(speechRecognitionResult);
}
Where by it's prompting the user to say something and then just getting hold of the Microphone input and converting it into Text, by calling the above mentioned method.
Let us run the code now:

Text to speech:
Just as above, we can define a method that can understand the keyed in text and convert it into text.static void OutputSpeechSynthesisResult(SpeechSynthesisResult speechSynthesisResult, string text)
{
switch (speechSynthesisResult.Reason)
{
case ResultReason.SynthesizingAudioCompleted:
Console.WriteLine($"Analyzing input for speech: [{text}]");
break;
case ResultReason.Canceled:
var cancellation = SpeechSynthesisCancellationDetails.FromResult(speechSynthesisResult);
Console.WriteLine($"CANCELED: Reason={cancellation.Reason}");
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={cancellation.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails=[{cancellation.ErrorDetails}]");
Console.WriteLine($"CANCELED: Ensure that you have correctly set the speech resource key and region values.");
}
break;
default:
break;
}
}
Just as the first example, it gets the code and then it converts the input as text.
But uh -- hang on. There is even more:
When I run the main methodd, I am passing on additional parameters:
async static Task Main(string[] args)
{
Console.WriteLine("Write something here, and let me say it out for you");
string inputText = Console.ReadLine();
Console.WriteLine("Would you like to hear it from a male or a female voice? Press F or M....");
string gender = Console.ReadLine();
var speechConfig = SpeechConfig.FromSubscription(speechKey, speechRegion);
if (gender == "F")
{
speechConfig.SpeechSynthesisVoiceName = "en-US-JennyMultilingualNeural";
}
else
{
speechConfig.SpeechSynthesisVoiceName = "en-US-AndrewMultilingualNeural";
}
using (var speechSynthesizer = new SpeechSynthesizer(speechConfig))
{
var speechSynthesisResult = await speechSynthesizer.SpeakTextAsync(inputText);
OutputSpeechSynthesisResult(speechSynthesisResult, inputText);
}
Console.WriteLine("Press any key to exit...");
Console.ReadKey();
}
It's asking which gender would you like to hear it from. Azure AI has a number of prebuilt voice synthesis recordings that can take any shape which you want to play it in.
So if we run it now:

The program reads out in a feminine voice with US accent, like how I have chosen in the screenshot above.
This apart:
a. It can convert any recording/meetings conversation into text as well. Simply giving the Speech resource access to Graph API, you can access any Microsoft Teams meeting and convert the same into Sentiments, emphasis and a lot of associated analytical parameters.
b. Speaker seaparation: making different speakers be split out in a conversation
c. It can also be called in a batch transcription API
d. Call summarization.
Interetsing?
Ok, let me be back soon with more such insights and cool hacks on Azure AI speech on another brand new blog. Till then, enjoy the winter and Christmas. Much love and Namaste like always💓💓💓
*This post is locked for comments